

Zwischen neuen Algorithmen und IT-Fortschritten können Maschinen jetzt immer komplexere Modelle lernen. Sie erzeugen hochwertige synthetische Daten wie fotorealistische Bilder und sogar Lebensläufe von fiktiven Menschen.
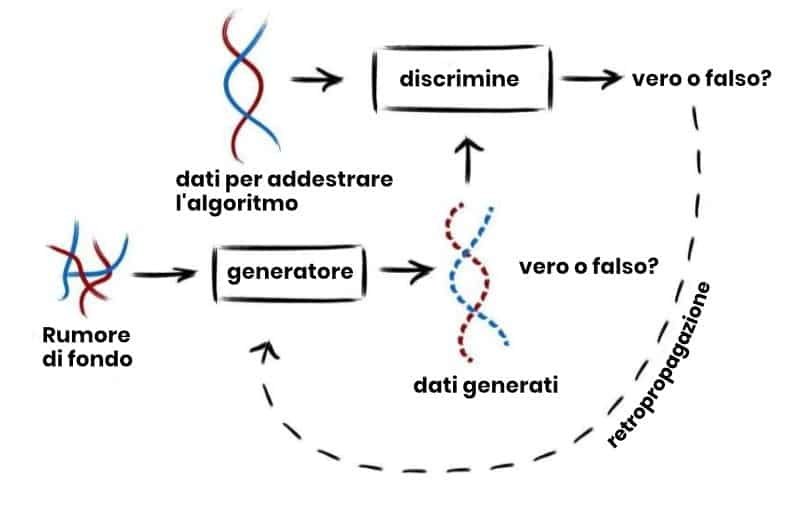
Uhr eine Studie, die in der internationalen Zeitschrift veröffentlicht wurde PLoS Genetics zeigt den fortgeschrittenen Einsatz von maschinellem Lernen für biometrische Daten. Aus vorhandenen Biobanken generiert das System ganze Blöcke des menschlichen Genoms, die nicht zu echten Menschen gehören, aber die Eigenschaften eines echten Genoms aufweisen.
Umgehen des Datenschutzproblems
„Bestehende Genomdatenbanken sind eine unschätzbare Ressource für biomedizinische Forschung," Er sagt Burak Jelmen, Erstautor der Studie und Junior Research Fellow für moderne Populationsgenetik an der Universität von Tartu. „Das Problem ist, dass sie aufgrund berechtigter ethischer Bedenken nicht öffentlich zugänglich sind oder durch langwierige und anstrengende Durchsetzungsverfahren geschützt werden. Dies schafft eine wichtige wissenschaftliche Barriere für Forscher. Ein maschinengeneriertes Genom, ein "künstliches Genom", kann uns helfen, das Problem in einem sicheren ethischen Rahmen zu überwinden.
:format(jpg):extract_cover()/https%3A%2F%2Fscx1.b-cdn.net%2Fcsz%2Fnews%2F800a%2F2021%2F13-machinelearn.jpg)
Das multidisziplinäre Team führte mehr Analysen durch, um die Qualität des durch maschinelles Lernen erzeugten Genoms im Vergleich zum realen zu bewerten. "Überraschenderweise ahmt dieses Genom die Komplexität nach, die wir in realen menschlichen Populationen beobachten können, und für die meisten Eigenschaften Sie sind nicht von den anderen Genomen der Biobank zu unterscheiden, mit denen unser Algorithmus trainiert wurde. Abgesehen von einem Detail: Sie gehören keinem Genspender “, sagte der DR. Luca Pagani, einer der führenden Autoren der Studie und Mitmobilitas Pluss.
Ein maschinengeneriertes Genom, ein "künstliches Genom", kann uns helfen, das Problem in einem sicheren ethischen Rahmen zu überwinden
Burak Jelmen
Ist es wirklich ein Originalgenom oder eine "Spuck" -Kopie?
Die Studie umfasst auch die Bewertung der Nähe des künstlichen Genoms zum realen Genom, um zu überprüfen, ob die Privatsphäre der Originalproben erhalten bleibt. „Während das Erkennen von Datenschutzlecks in Tausenden von Genomen wie die Suche nach einer Nadel im Heuhaufen erscheint, können wir durch die Kombination mehrerer statistischer Messgrößen alle Modelle genau überwachen. Interessanterweise führt die detaillierte Untersuchung komplexer Dispersionsmuster wiederum zu weiteren Verbesserungen bei der Bewertung von GAN und es wird das Feld des maschinellen Lernens befeuern “. Zu sagen, es ist Dr. Flora Jay, Studienkoordinator und Forscher des CNRS (Französisches Nationales Zentrum für wissenschaftliche Forschung).
Alles in allem sind die Ansätze des maschinellen Lernens bereits vorhanden Volti, Biografien und viele andere Funktionen zu einer Handvoll imaginärer Menschen. Wir wissen jetzt auch mehr über ihre Biologie. Diese fiktiven Menschen mit realistischen Genomen könnten als experimentelle Bank anstelle von realen Genomen dienen, die nicht öffentlich verfügbar sind.

