
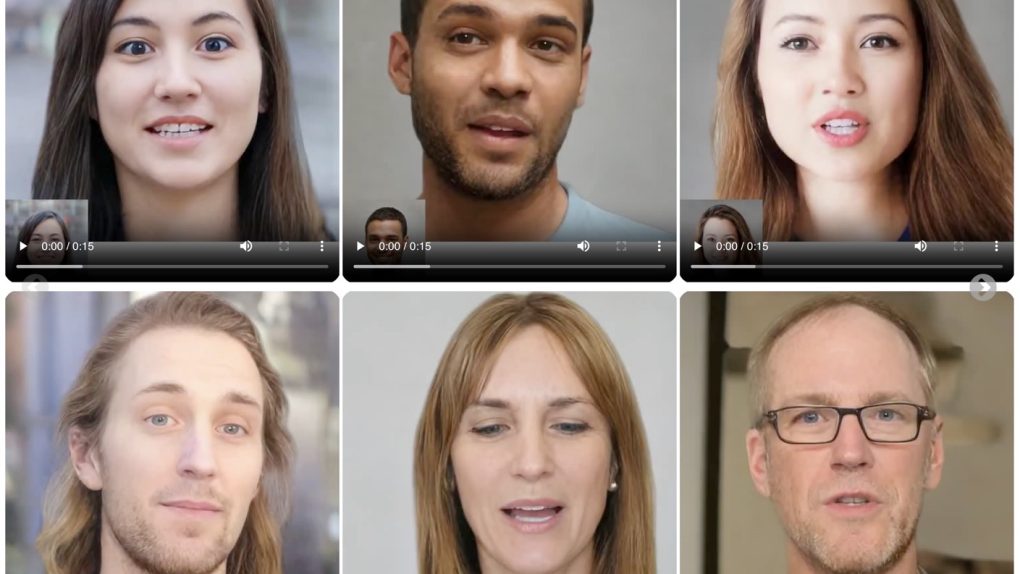
Die Zeit der KI-Assistenten rückt immer näher: Die Interaktion mit digitalen Gesichtern und Avataren wird schnell zu einem festen Bestandteil unseres täglichen Lebens. Wie weit können diese digitalen Gesichter gehen, um den Realismus einer realen Person nachzubilden? Sehr weit weg, gemessen an VASA-1, dem innovativen Modell der künstlichen Intelligenz, das gerade von Microsoft Research entwickelt wurde. Hier finden Sie das Papier.
VASA-1 kann aus einer einzigen Bild- und Audiodatei in Echtzeit ultrarealistische Videos sprechender Gesichter erstellen. Es wird die Grenzen dessen erweitern, was bei der Erstellung digitaler Avatare möglich ist, mit Anwendungen, die von Videoanrufen über Unterhaltungsinhalte bis hin zur Verbesserung der Zugänglichkeit für Menschen mit Hörbehinderungen reichen.

VASA-1, beispielloser Realismus
Was VASA-1 wirklich revolutionär macht, ist der Grad an Realismus, den es erreichen kann. Die von diesem KI-Modell generierten Videos sind von denen echter Menschen praktisch nicht zu unterscheiden.
Möglich wird dies durch eine Reihe innovativer Features. Erstens, VASA-1 bietet eine perfekte Synchronisierung zwischen Lippenbewegungen und Audio. Unabhängig von der Sprache oder dem Vorhandensein von Hintergrundgeräuschen bewegen sich die Lippen des Avatars perfekt synchron mit den gesprochenen Worten und erzeugen so einen überraschend realistischen Effekt.
Darüber hinaus ist VASA-1 in der Lage, ein breites Spektrum an Gesichtsausdrücken zu erfassen und wiederzugeben. von den subtilsten Nuancen bis zu den ausgeprägtesten Emotionen. Dies verleiht den generierten Avataren ein zusätzliches Maß an Tiefe und Authentizität und die „digitale Menschen".
Schließlich werden Kopfbewegungen auf natürliche und flüssige Weise erzeugt, Dies trägt zum Eindruck bei, dass man vor einer realen Person steht und nicht vor einem statischen Bild.

Echtzeitgenerierung und hohe Qualität
Ich finde die Fähigkeit des VASA-1, diese ultrarealistischen Videos in Echtzeit zu erzeugen, beeindruckend. Es hat derzeit eine Auflösung von 512 x 512 Pixeln und eine Geschwindigkeit von bis zu 40 Bildern pro Sekunde, aber es handelt sich um live sprechende Avatare, ohne Verzögerungen oder Unterbrechungen.
Dies ebnet den Weg für eine Reihe innovativer Anwendungen. Mit VASA-1 könnten beispielsweise personalisierte Avatare für Videoanrufe erstellt werden, wodurch virtuelle Interaktionen ansprechender und realistischer werden. Es könnte auch verwendet werden, um interaktive Charaktere in Videospielen zu generieren oder um lehrreiche und unterhaltsame Videoinhalte mit virtuellen Moderatoren zu erstellen.
Auf dem Weg zu mehr Barrierefreiheit
Eine der interessantesten möglichen Anwendungen von VASA-1 betrifft die Zugänglichkeit. Durch die Generierung von Videos sprechender Gesichter aus einer Audiodatei könnte dieses KI-Modell verwendet werden, um barrierefreie Versionen von Videoinhalten für Menschen mit Hörbehinderungen zu erstellen.
Stellen Sie sich vor, Sie könnten sich eine Rede oder einen Vortrag mit einem Sprecher-Avatar ansehen, der die Worte synchron mit dem Ton deutlich artikuliert. Dadurch könnten die Inhalte für Menschen mit Hörproblemen deutlich nutzbarer werden und neue Möglichkeiten des Lernens und der Teilnahme eröffnen.
Die Zukunft von VASA-1 und virtueller Kommunikation
Microsoft-Forscher sind damit nicht zufrieden und arbeiten bereits daran, die Leistung von VASA-1 weiter zu verbessern. In Zukunft können wir sprechende Avatare in noch höherer Qualität, noch flüssiger und mit höherer Auflösung erwarten. Ganz zu schweigen von den Zeiten und Kosten für Filme und Animationen: Sie werden sich völlig ändern.
Diejenigen unter Ihnen, die sich an die bahnbrechende TV-Serie erinnern.Max Headroom„? Dort wurde ein echter Journalist als virtueller Avatar „wiederbelebt“. Eine visionäre Serie vor 30 Jahren, die bald von den Fakten völlig übertroffen wird. Mit der Weiterentwicklung von VASA-1 und ähnlichen Technologien könnte die Grenze zwischen virtueller Kommunikation und persönlicher Interaktion zunehmend verschwimmen.
Natürlich wirft diese Perspektive auch ethische und soziale Fragen auf. Es wird wichtig sein, Richtlinien und Vorschriften zu entwickeln, um einen verantwortungsvollen und transparenten Einsatz dieser Technologien zu gewährleisten, die Privatsphäre zu schützen und potenziellen Missbrauch wie die Erstellung von Deepfakes zu verhindern.
Allerdings sind die potenziellen Vorteile von Modellen wie VASA-1 enorm.
Von ansprechenderer Kommunikation bis hin zu verbessertem Lernen, von interaktiverer Unterhaltung bis hin zu besserer Zugänglichkeit – die Anwendungsmöglichkeiten sind vielfältig und vielversprechend.
VASA-1 bietet uns einen faszinierenden Einblick in eine Zukunft, in der virtuelle Kommunikation zunehmend nicht mehr von persönlicher Kommunikation zu unterscheiden sein wird. Es ist eine Zukunft, in der ultrarealistische Avatare nicht nur Worte, sondern auch Emotionen, Ausdrücke und Präsenz vermitteln können. Eine Zukunft, in der die physische Distanz weniger ein Hindernis darstellt und die Zugänglichkeit zu Inhalten erheblich verbessert wird.
Ich bin wirklich gespannt, wie VASA-1 (und seine Nachfolger) die Art und Weise, wie wir kommunizieren, lernen und uns unterhalten, in den kommenden Jahren verändern wird. Die Revolution des digitalen Gesichts hat gerade erst begonnen und die Zukunft scheint realistischer denn je.

